Source: Hall, Cox, Dickerson, Kannan, Kulkarni, and Schmidt[34]
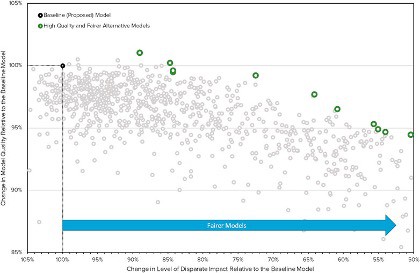
The modeler built ten models that reduced the level of disparate impact. Of those, two increased on prior levels of model quality (predictive power of default) and only one demonstrated a reduction in model quality of more than five percentage points. One conclusion would be adopting any model that could achieve an improvement in both criteria. Alternatively, regulators could lend support for improvements in fairness that resulted in only minimal concessions to model quality.
We contend that the Agencies should commit to the latter approach. Such a system would require the Agencies to indicate what level of unfairness triggers a need for a new model. A post-processing measure, such as an adverse impact ratio, would provide clarity. Subsequently, the Agencies should indicate a minimum standard for fairness and appropriate ratios for improvements in fairness relative to losses in model quality.
c) Provide guidance on how financial institutions should test their algorithmic underwriting models to mitigate against biases against protected class members.
Methods for mitigating bias in AI/ML models take one of three general forms: pre-process, where disparities in training data are addressed; in-process, where algorithms are trained to remove disparities while “learning;” and post-process, where models are altered in response to observed outcomes.
Pre-processing approaches consider the training data set used by the modeler. For the context of protecting against discriminatory outcomes, pre-processing can avoid situations where the data used to build a model is incomplete, not representative of the broader population, or if it is inconsistent with real-world contexts. If such procedures are not implemented, then a “garbage-in garbage-out” problem may occur. An AI/ML model is only as good as its data.
The agencies can implement methods to safeguard against overfitting by creating a publicly maintained data set for testing. While compliance efforts have tended to focus on outcomes,[35] an emphasis on pre-processing techniques has its own merits.
In-processing techniques consist of interventions made during the training period of model building. Adversarial debiasing allows a modeler to see which attributes contribute the most to unfairness and then change the model’s weightings to optimize for fairness.[36]
A virtue of pre-processing and in-processing techniques is that lenders can conduct these efforts before introducing a model to the marketplace.
Post-processing approaches rely on means for measuring bias in completed models. “Drop-one” systems, where variables are removed iteratively to see their “marginal effect” on a fairness criterion, are an example of a post-processing approach. Others may involve re-construction of an algorithm rarely than merely the “drop” of one variable. Post-processing techniques can identify sources of discrimination and measure the impact of a change in a model to fairness, accuracy, or other criteria.
AIRs and standardized mean differences do not suggest specific changes, but they can measure disparate impact in a model. Although they do bear the virtue of simplicity, post-process approaches can lead to sub-optimal resolutions. These approaches can be used to create comparisons between “unfair” and “fair” models, which could then become the basis for some lenders to assert that fairness is costly, or alternatively to make it satisfactory to stop at a “slightly less unfair” model as opposed to re-iterating to a fair one.
Post-processing techniques are relatively simple to implement. From a regulatory perspective, they have value because they allow an agency to make a judgment about a system without stipulating how it should be changed. Nonetheless, the best way to simplify a model is not through post-processing but instead by beginning with an explainable training data set and model.
d) State that lenders are responsible for algorithms and predictive models that have a disparate impact on members of protected classes, even if they are created or maintained by third parties. State that lenders should conduct their model risk assessments using independent sources.
Agencies should encourage lenders to conduct periodic audits of their training data sets and models.
e) Provide guidance on the collection and analysis of demographic data for self-testing privileges.
Efforts by lenders to conduct self-testing for compliance with fair lending rules confront challenges due to a lack of clarity from the Agencies on collecting demographic data. At the moment, mortgage lenders must collect and report data on aspects of demographic data under Regulation C implementing the Home Mortgage Disclosure Act, and a similar requirement is expected to be implemented for the collection of small business lending data pursuant to Section 1071 of the Dodd-Frank Wall Street Reform and Consumer Protection Act. However, Regulation B is not clear on when and for what purposes lenders can collect data when offering other types of credit products.[37]
As a result, compliance professionals use statistical methods to approximate the demographic makeup of their customers. In 2014, the CFPB published a report on the effectiveness of the Bayesian Improved Surname Geocoding (BISG) proxy method, noting that it presented improvements over previous approaches that only used surnames or geocoding.[38]
Nonetheless, BISG still has certain shortcomings. Most notably, while compliance professionals can use BISG to estimate the overall demographic makeup of a group of applicants, they cannot have certainty over the demographic identity of individual applicants. Moreover, given that rates of inter-racial marriage are increasing, the predictive power of the surnames in BISG may decrease. The same concerns exist for geocoding in areas with high rates of gentrification. As well, the predictive power of any BISG analysis faces constraints with smaller sample sizes. Despite these limitations, BISG is accepted by both regulators and responsible lenders as a diagnostic tool to proxy for race and ethnicity because it is reasonably accurate.
Lenders should continue to enhance their proxy methodologies through the use of self-testing. To facilitate improvements and simplify the process, lenders could benefit from considering demographic data to assist with their internal fair lending compliance procedures. However, they often hesitate to do so for fear of exposing their organizations to additional compliance risk. We believe that lenders could benefit from new guidance that clarifies the extent to which they can use demographic data for self-testing, as long as that data is not included in marketing, underwriting, servicing, fraud protection, or other credit-related decisions.
In addition, please see part B of our response to Questions 4 and 5.
Conclusion
NCRC applauds the decision by the Agencies to address the use of artificial intelligence, machine learning, and alternative data.
NCRC believes that future supervision, rulemaking, and enforcement of AI and ML should focus on the principles of equity, transparency, and accountability.
Our comments have focused on concerns related to the explainability of models, accountability, the use of alternative data, and the need to build safeguards to prevent discriminatory practices.
NCRC urges the Agencies to ensure that the use of AI and ML develops in ways that are non-discriminatory. As the use of these technologies becomes increasingly widespread, urgency will build for regulators to establish safeguards. The Agencies must address these questions as soon as possible, as we face an inflection point where algorithmic underwriting may develop in ways that either add to or undermine access to fair, safe, and inclusive financial services.
We encourage the Agencies to provide guidance on how financial institutions should deploy artificial intelligence and machine learning. If the Agencies can give clear guidance on the issues outlined in our comment, it will clarify that well-intentioned actors need to build and market safe products. Indeed, without substantial changes, lenders will be unable to adequately explain adverse decisions or establish compliance systems that empower the kinds of frequent self-testing efforts that machine learning requires.
To reduce the chance of digital redlining, the Agencies should insist that all lenders build explainable models. Explainable models create safeguards against digital redlining.
Financial service regulators should hold all lenders accountable for testing their models for disparate impact, including those using alternative data developed by the lender or purchased from a third party. We encourage the Agencies to provide guidance on how and when lenders should implement alternatives.
Making a commitment to equity must include explicitly identifying discriminatory practices as a type of risk, by providing guidance on the disparate impact standard by updating the language to state that the creditor practice must meet a “substantial, legitimate, nondiscriminatory interest, and by emphasizing diversity in hiring.
Please contact me, Brad Blower (bblower@ncrc.org), or Adam Rust (arust@ncrc.org) if we can provide clarity on any of these issues or others.
Sincerely,
National Community Reinvestment Coalition
| Affordable Homeownership Foundation, Inc. |
| California Reinvestment Coalition |
| CASA of Oregon |
| Clarifi |
| Community Service Network |
| Educational |
| Fair Finance Watch |
| Fair Housing Center of Central Indiana |
| HOME of Greater Cincinnati |
| Housing Justice Center |
| Housing on Merit |
| LINC UP |
| MakingChange, Inc |
| Maryland Consumer Rights Coalition |
| Metro North Community Development Corp. |
| National Association of American Veterans, Inc. |
| Northwest Indiana Reinvestment Alliance |
| Olive Hill Community Economic Development Corporation, Inc |
| People’s Self-Help Housing |
| Public Good Law Center |
| Southern Dallas Progress Community Development Corporation |
| Stark County Minority Business Association |
| United South Broadway Corporation |
APPENDIX:
Statement on Request for Guidance on Implementation of Disparate Impact Rules under ECOA
A proposal by National Community Reinvestment Coalition’s Innovation Council for Financial Inclusion.
![]()
Preventing discrimination in the use of algorithms and predictive models is crucial for a fair financial system in the digital age. As a group of both consumer advocates and financial services companies, we have found a shared interest in encouraging a fair lending regulatory framework that can truly address the risk of digital discrimination, while also promoting technology and data innovation that has the potential to increase financial inclusion and lower prices for consumers. We believe the avoidance of disparate impact is the core of the solution.
We appreciate disparate impact’s statistical, outcomes-based approach to identifying discrimination. By assessing outcomes, rather than inputs, disparate impact addresses discrimination that can arise when decisions are the result of algorithms or data, rather than human intent. We also believe this outcomes-based approach establishes disparate impact as a pro-innovation framework for preventing discrimination. This is because it can accommodate advances in credit modeling, artificial intelligence, machine learning, and alternative data, which have the potential to increase financial inclusion, while at the same time holding these technologies accountable for addressing potential discriminatory impact. This combination of innovation and outcomes-based accountability will produce the most fair, inclusive, consumer friendly financial services ecosystem, and allow innovation to help address the “financial services deserts” by bringing the benefits of the financial system to those who are currently underserved.
We ask that the CFPB update its guidance on disparate impact to reinforce the Equal Credit Opportunity Act (ECOA) and Regulation B, for the digital age, in a manner that is designed to encourage a fair, innovative and more inclusive financial system. We believe the need for updated guidance is even greater as a result of HUD’s 2020 Disparate Impact Rule. HUD’s rule, currently enjoined in federal court, undermines the disparate impact framework when used under the Fair Housing Act, and if followed could become a misguided template for regulation of disparate impact under ECOA,
To encourage innovation and financial inclusion, the CFPB should provide further guidance on disparate impact under ECOA and Regulation B by:
- Specifically stating that the disparate impact framework applies to both traditional and technological underwriting techniques, including those that use artificial intelligence, machine learning, algorithms, and the use of alternative data.
- Aligning the “legitimate business need” standard to the 2013 HUD rule.We call on the CFPB to update Regulation B and its Commentary to establish that a creditor practice must meet a “substantial, legitimate, and non-discriminatory interest” that cannot reasonably be achieved through another practice that has a less discriminatory effect. This clarification is important to reduce uncertainty about what constitutes a “legitimate business need” and to minimize the risk that a lender could assert that greater profit alone is a sufficient business justification without considering the harm caused from disparate impact. We suggest the CFPB also provide examples of how lenders can demonstrate legitimate business need.
- Establishing statistical standards of “practical significance” to clarify when disparities would rise to the level of potentially constituting grounds for a disparate impact discrimination claim. This would increase accountability while providing clarity and ease of administration for responsible compliance programs. Such clarity could have the added benefit of giving lenders the freedom to further innovate their lending.
- d) Clarifying how lenders may deploy alternativeanalyses to search for less-discriminatory alternatives to a practice or data variable found to result in a disparity. Guidelines should addresswhen and how a review for a less-discriminatory alternative is appropriate, and the extent that a guidance could include use case-specific models for defensible practices.
- e) Providing additional guidance on the use of the self-testing privilege to gather data on customer race, ethnicity, or gender, and the useof self-testing, including methods other than BISG.
This guidance would provide more regulatory certainty in loan product types beyond mortgage lending. With additional clarity from the Bureau, more lenders could implement robust self-testing and remediation protocols.
We believe that the above guidance will foster more effective monitoring of disparate impact in compliance with ECOA, while also providing greater access to affordable credit.
[1] 12 C.F.R. pt. 1002, Supp. I, ¶ 1002.2(p)–4
[2] The group includes the National Fair Housing Alliance, Fair Play AI, ACLU, Lawyer’s Committee, Upturn, AI Blindspot, FinRegLab, Tech Equity Collaborative, BLDS, and Relman Colfax.
[3] The members of NCRC’s Innovation Council are Affirm, Lending Club, PayPal, Square, Oportun, and Varo.
[4] FICO. “The State of Responsible AI.” FICO, May 28, 2021. https://mobileidworld.com/fico-urges-businesses-prioritize-ethics-ai-development-052805/.
[5] FICO. “The State of Responsible AI.” FICO, May 28, 2021. https://mobileidworld.com/fico-urges-businesses-prioritize-ethics-ai-development-052805/.
[6] Ajay Tiwari. “Application of Monotonic Constraints in Machine Learning Models: A Tutorial on Enforcing Monotonic Constraints in XGBoost and LightGBM Models.” Medium, May 1, 2020. https://medium.com/analytics-vidhya/application-of-monotonic-constraints-in-machine-learning-models-334564bea616.
[7] Joy Buolamwini and Timnit Gebru. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” In Proceedings of Machine Learning Research, 81:1–15. New York, NY, 2018. http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf.
[8] P. Jonathon Phillips, Carina A. Hahn, Peter C. Fontana, David A. Broniatowski, and Mark A. Przybocki. “Four Principles of Artificial Intelligence.” Gaithersburg, Maryland: National Institute of Standards and Technology, August 2020. https://www.nist.gov/document/four-principles-explainable-artificial-intelligence-nistir-8312.
[9] Rudin, Cynthia and Radin, Joanna. “Why Are We Using Black Box Models in AI When We Don’t Need To? A Lesson From An Explainable AI Competition.” Harvard Data Science Review 1, no. 2 (2019). https://doi.org/10.1162/99608f92.5a8a3a3d.
[10] European Union. Proposal for a Regulation laying down harmonized rules on artificial intelligence (n.d.). https://digital-strategy.ec.europa.eu/en/library/proposal-regulation-laying-down-harmonised-rules-artificial-intelligence.
[11] National Community Reinvestment Coalition. “2020 Policy Agenda for the 116th Session of Congress,” May 2020. https://ncrc.org/2020-policy-agenda-for-the-116th-session-of-congress/.
[12] Consumer Financial Protection Bureau. “Fair Lending Report of the Bureau of Consumer Financial Protection.” Washington, DC: Consumer Financial Protection Bureau, April 2020. https://files.consumerfinance.gov/f/documents/cfpb_2019-fair-lending_report.pdf.
[13] Consumer Financial Protection Bureau. “Appendix C to Part 1002 — Sample Notification Forms.” Interactive Bureau Regulations 12 CFR Part 1002 (Regulation B), n.d. https://www.consumerfinance.gov/rules-policy/regulations/1002/c/.
[14] Consumer Financial Protection Bureau. “Fair Lending Report of the Bureau of Consumer Financial Protection.” Washington, DC: Consumer Financial Protection Bureau, April 2020. https://files.consumerfinance.gov/f/documents/cfpb_2019-fair-lending_report.pdf.
[15] Consumer Financial Protection Bureau. “Tech Sprint on Electronic Disclosures of Adverse Action Notices.” Innovation at the Bureau, October 5, 2020. https://www.consumerfinance.gov/rules-policy/innovation/cfpb-tech-sprints/electronic-disclosures-tech-sprint/.
[16] Department of Housing and Urban Development. “Implementation of the Fair Housing Act’s Discriminatory Effects Standard 24 CFR 100.” Federal Register, February 15, 2013. Pg. 11,460 https://www.hud.gov/sites/documents/DISCRIMINATORYEFFECTRULE.PDF.
[17] Katherine Welbeck and Ben Kaufman. “Domino: A Blog about Student Debt.” Student Borrower Protection Center. Fintech Lenders’ Responses to Senate Probe Heighten Fears of Educational Redlining (blog), July 31, 2020. https://protectborrowers.org/fintech-lenders-response-to-senate-probe-heightens-fears-of-educational-redlining/.
[18] Cynthia Rudin. “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.” Nature Machine Intelligence 1, no. 5 (May 2019): 206–15.
[19] Brandon Lardy. “A Revealing Look at Racial Diversity in the Federal Government: Diversity, Equity, and Inclusion.” Partnership for Public Service, July 14, 2020. https://ourpublicservice.org/blog/a-revealing-look-at-racial-diversity-in-the-federal-government/.
[20] Federal Trade Commission. “Big Data: A Tool for Inclusion or Exclusion? Understanding the Issues.” Washington, DC, January 6, 2016. https://www.ftc.gov/system/files/documents/reports/big-data-tool-inclusion-or-exclusion-understanding-issues/160106big-data-rpt.pdf.
[21] Federal Trade Commission. “Fair Credit Reporting Act 15 U.S.C § 1681,” September 2018. https://www.ftc.gov/system/files/documents/statutes/fair-credit-reporting-act/545a_fair-credit-reporting-act-0918.pdf.
[22] Elevate Credit, Inc. “Elevate: Leading the Path to Progress.” Annual Report for 2018, March 2019. https://www.annualreports.com/HostedData/AnnualReportArchive/e/NYSE_ELVT_2018.pdf.
[23] J. Jatgiana and C. Lemiuex. “The Role of Alternative Data and Machine Learning in Fintech: Evidence from the Lending Club Platform.” Philadelphia, Pennsylvania: Federal Reserve Bank of Philadelphia, January 2019.
[24] Preston Gralla. “Computerworld: Opinion” Amazon Prime and the Racist Algorithms (blog), May 11, 2016. https://www.computerworld.com/article/3068622/amazon-prime-and-the-racist-algorithms.html.
[25] Kenneth P. Brevoort, Philipp Grimm, and Michelle Kambara. “Data Point: Credit Invisibles.” Washington, DC: Consumer Financial Protection Bureau, May 2015. https://files.consumerfinance.gov/f/201505_cfpb_data-point-credit-invisibles.pdf.
[26] “Comments of the American Bankers Association, Consumer Bankers Association, and Housing Policy Council in Support of Proposed Amendments to the Fair Housing Act’s Disparate Impact Standard to Reflect United States Supreme Court Precedent,” October 18, 2019. https://www.aba.com/-/media/documents/comment-letter/joint-hud-disparate-impact-101819.pdf.
[27] Emily Flitter. “Big Banks’ ‘Revolutionary Request: Please Don’t Weaken This Rule.” New York Times. July 16, 2020. https://www.nytimes.com/2020/07/16/business/banks-housing-racial-discrimination.html
[28] National Community Reinvestment Coalition, Lending Club, Affirm, Varo Bank, Oportun, PayPal, and Square. “NCRC, Fintechs Call On CFPB To Clarify Applying Fair Lending Rules To Artificial Intelligence.” National Community Reinvestment Coalition, June 29, 2021. https://www.ncrc.org/ncrc-fintechs-call-on-cfpb-to-clarify-applying-fair-lending-rules-to-artificial-intelligence/.
[29] Consumer Financial Protection Bureau. “Responsible Business Conduct: Self-Policing, Self-Reporting, Remediation, and Cooperation,” June 25, 2013. https://files.consumerfinance.gov/f/201306_cfpb_bulletin_responsible-conduct.pdf.
[30] Policy Statement on Discrimination in Lending” (59 Fed. Reg. 18266 (April 15, 1994)); OCC Bulletin 1997-24, “Credit Scoring Models: Examination Guidance”; OCC Bulletin 2011-12, ‘sound Practices for Model Risk Management: Supervisory Guidance on Model Risk Management”; OCC Bulletin 2013-29, “Third-Party Relationships: Risk Management”; and OCC Bulletin 2017-43, “New, Modified, or Expanded Bank Products and Services: Risk Management Principles.
[31] Consumer Financial Protection Bureau. “The Early Effects of the COVID-19 Pandemic on Credit Applications.” Special Issue Brief. Office of Research, April 2020. https://files.consumerfinance.gov/f/documents/cfpb_issue-brief_early-effects-covid-19-credit-applications_2020-04.pdf.
[32] Nikita Kozodoi, Johannes Jacob, and Stefan Lessmann. “Fairness in Credit Scoring: Assessment, Implementation, and Profit Implications.” European Journal of Operational Research 295, no. 1 (June 2021). https://doi.org/10.1016/j.ejor.2021.06.023.
[33] Nicholas Schmidt and Bryce Stephens. “An Introduction to Artificial Intelligence and Solutions to the Problems of Algorithmic Discrimination.” Algorithmic Discrimination 73, no. 2 (2019): 130–45.
[34] Patrick Hall, Benjamin Cox, Steven Dickerson, Arjun Ravi Kannan, Raghu Kulkarni, and Nicholas Schmidt. “A United States Fair Lending Perspective on Machine Learning.” Frontiers of Artificial Intelligence, June 7, 2021. https://doi.org/10.3389/frai.2021.695301.
[35] Patrick Hall, Benjamin Cox, Steven Dickerson, Arjun Ravi Kannan, Raghu Kulkarni, and Nicholas Schmidt. “A United States Fair Lending Perspective on Machine Learning.” Frontiers of Artificial Intelligence, June 7, 2021. https://doi.org/10.3389/frai.2021.695301.
[36] Using Adversarial Debiasing to Reduce Model Bias and One Example of Bias Mitigation in In-Processing Stage. “Using Adversarial Debiasing to Reduce Model Bias: One Example of Bias Mitigation in In-Processing Stage.” Towards Data Science (blog), April 21, 2020. https://towardsdatascience.com/reducing-bias-from-models-built-on-the-adult-dataset-using-adversarial-debiasing-330f2ef3a3b4.
[37] Consumer Financial Protection Bureau. “12 CFR § 1002.15(b)(1)(ii) and commentary – Incentives for Self-Testing and Self-Correction,” n.d. https://www.consumerfinance.gov/rules-policy/regulations/1002/15/.
[38] Consumer Financial Protection Bureau. “Using Publicly Available Information to Proxy for Unidentified Race and Ethnicity: A Methodology and Assessment.” Washington, D.C.: CFPB, Summer 2014. https://files.consumerfinance.gov/f/201409_cfpb_report_proxy-methodology.pdf.
